






了解係統總線的活動情況可幫助開發工程師顯著改善嵌入式應用的性能。過去,由於(yu) 嵌入式處理器缺乏複雜的軟硬件結合特性,因此監測係統總線的活動情況是一項挑戰性難題。在係統級了解應用程序的行為(wei) 對於(yu) 有效利用係統資源非常關(guan) 鍵,這些資源包括外部存儲(chu) 器、DMA控製器、仲裁、係統總線互連等。
Blackfin BF54x係列處理器提供性能計數器(指標寄存器),可幫助應用開發工程師在係統級別了解應用程序的行為(wei) 。在掌握應用程序行為(wei) 後,開發工程師可使用一些係統優(you) 化技術來提高性能和降低功耗。
在本文中,將介紹性能指標寄存器的各種配置,並提供在Blackfin處理器上利用它們(men) 的軟硬件接口實例。此外,還針對一些典型的應用情形給出了提高性能的方法。
指標寄存器的定義(yi)
在典型的實際應用中有多種資源,如內(nei) 核處理器、外設DMA,以及可同時訪問外部存儲(chu) 器和幾個(ge) 係統總線的MDMA(存儲(chu) 器到存儲(chu) 器的DMA)。性能指標寄存器提供了一種捕捉外部存儲(chu) 器組訪問數、頁錯失數、總線流量數和總線轉向數的方式,有效地利用從(cong) 這些寄存器獲得的數據可顯著提高係統的資源利用率。
表1是Blackfin BF54x係列處理器提供的指標寄存器及其簡要說明。

我們(men) 可以使用存儲(chu) 器組讀/寫(xie) 寄存器、組激活計數寄存器和總線轉向寄存器來改善應用程序的代碼和數據外部存儲(chu) 器布局。授權計數寄存器(EBIU_DDRGCx)可幫助合理定義(yi) 係統仲裁策略,還能實現高的係統吞吐率。
我們(men) 可以利用代碼和數據項映射到外部存儲(chu) 器的時間區間和空間位置來減少外部存儲(chu) 器的延遲。在通常情況下,要捕捉應用程序的空間位置和時間區間,需要記錄在程序執行期間的代碼和數據對象的蹤跡。然而,對於(yu) 一些簡單的應用程序來說,利用指標寄存器的關(guan) 鍵數據就可以揭示外部存儲(chu) 器中的不良映射代碼和數據項。
下麵探討一些應用情形,以及利用從(cong) 這些指標寄存器得到的信息進行優(you) 化的一些簡單技術。
示例的使用
下麵將介紹如何分析和解讀從(cong) 指標寄存器獲得的信息,並在此基礎上討論如何運用簡單的優(you) 化技術來提高應用的性能。
1 示例1
在這個(ge) 示例中,多個(ge) 數據緩存映射到外部存儲(chu) 器,並使用存儲(chu) 器DMA通道把一組緩存的內(nei) 容複製到另一組緩存。本實驗中共有4個(ge) 緩存,規模均為(wei) 32KB。所有緩存均映射到DDR的Bank0並從(cong) 地址0×0開始連續放置。圖1顯示了映射到外部存儲(chu) 器的四個(ge) 緩存的默認布局。在這個(ge) 例子中,兩(liang) 個(ge) 存儲(chu) 器DMA通道采用自動緩衝(chong) 模式不間斷地把兩(liang) 個(ge) 緩存的內(nei) 容傳(chuan) 送到另外兩(liang) 個(ge) 緩存。下麵介紹一個(ge) 三步過程,利用從(cong) 指標寄存器獲得的信息並相應地使用一些係統優(you) 化技術,該過程可把性能提高到原係統的1.5倍。
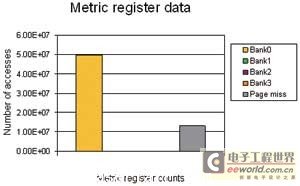
圖1 未優(you) 化時的指標寄存器數據
第1步 基本係統性能
我們(men) 使用係統的平均吞吐率來量化係統的性能。平均吞吐率按下式計算:
平均吞吐率=“讀出和寫(xie) 入DDR存儲(chu) 器的數據字節總數”/秒
係統總線活動的時間區間使用內(nei) 核計時器來設置。通過設置,該定時器在到達實驗設定的時間區間時產(chan) 生一個(ge) 中斷。該計時器在存儲(chu) 器DMA通道開始啟用之前啟動,然後,在內(nei) 核計時器ISR中禁用存儲(chu) 器DMA通道。傳(chuan) 輸的數據量用相應的計數器在DMA通道的中斷服務程序中進行測量。每次緩存傳(chuan) 輸產(chan) 生一個(ge) 中斷,DMA ISR每調用一次則計數器加1。由於(yu) 所有的存儲(chu) 器DMA通道均運行在自動緩衝(chong) 模式,在最終計算吞吐率時,通道中斷延時不需計算在內(nei) 。對於(yu) 這個(ge) 測量,定時器中斷延時由於(yu) 數值很小不計算在內(nei) 。
表2顯示了該係統的基準性能。從(cong) 該表可以看出,即使是這樣一個(ge) 簡單的係統,我們(men) 也隻利用了可用總帶寬的一小部分。指標寄存器使我們(men) 可以看到係統總線的活動情況,並幫助我們(men) 明白性能較低的原因。基於(yu) 這些信息,我們(men) 將能夠應用某些優(you) 化技術來提高性能。

第2步 使用指標寄存器
對於(yu) 這些情況,外部存儲(chu) 器延遲通常是吞吐率低的原因。我們(men) 將首先考察DDR讀/寫(xie) 訪問總數和離頁DDR訪問總數。
從(cong) 圖1可以看出,計數寄存器的讀取和寫(xie) 入訪問表明,訪問隻針對一個(ge) 組(組0),頁激活數占訪問總數的25%。這意味著,由於(yu) 緩存影射到組0的不同頁,DMA訪問在同一組中的空間位置很小。由於(yu) 源緩存和目標緩存在不同的頁上,每次DMA訪問均存在一次離頁訪問。
第3步 提高性能
把緩存放在不同的DDR組中可減少離頁訪問。如果把緩存放在不同的組中,則僅(jin) 當某個(ge) 通道穿越頁邊界時才會(hui) 發生離頁訪問。Blackfin BF54x的DDR控製器支持最多同時打開8個(ge) 內(nei) 部DDR組,因此可以把四個(ge) 緩存分別映射到不同的組。
2 示例2
在上麵的例1中,隻有很少的資源(兩(liang) 個(ge) MDMA通道)訪問單個(ge) DDR存儲(chu) 器組,係統行為(wei) 在一段時間內(nei) 不變。因此,可通過提取指標寄存器的快照來理解係統總線的活動並捕捉空間位置。在更為(wei) 實際的係統中,可能有多個(ge) 資源(內(nei) 核、多個(ge) DMA通道)訪問多個(ge) DDR存儲(chu) 器組和係統總線,致使在較小的時間區間內(nei) DDR數據訪問模式迅速變化。在這些情況下,難以僅(jin) 僅(jin) 利用指標寄存器的一個(ge) 快照來捕捉空間位置和係統行為(wei) 。因此,必須捕捉在應用執行過程中在多個(ge) 點的總線活動情況來探索空間位置。
為(wei) 了說明這一點,考慮這樣一個(ge) 情況,總線在時間區間T的活動表明,對所有組的訪問是均衡的,但離頁訪問比例較高,但在較小時間區間(T1、T2,其中T1+T2=T)中記錄的總線活動表明對各組的訪問是不均衡的,見圖2。如果緩存布局可對時間區間T1和T2分別進行優(you) 化,則有可能顯著改善係統性能。
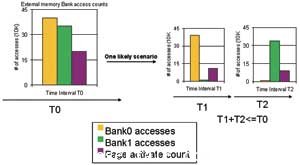
圖2 在時間區間T、T1和 T2的係統總線活動(T > T1+T2)
困難在於(yu) 如何找到對係統資源的訪問方式始終如一,進而可使用一組相同優(you) 化技術的時間區間。這可能需要對應用程序進行多次迭代分析。
定期捕捉指標寄存器數據的實驗裝置
在本節中,介紹定期記錄指標寄存器數據的實驗裝置。如圖3所示,一台PC用作主機,通過利用JTAG接口進行通信的後台遙測通道(BTC)收集來自Blackfin的數據。數據記錄程序運行在PC上,並定期向Blackfin處理器發送BTC指令。作為(wei) 回應,Blackfin處理器把指標寄存器的快照發送給主機。
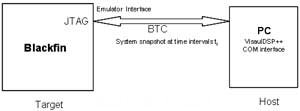
圖3 定期捕捉指標寄存器數據的實驗裝置
Blackfin處理器使用一個(ge) 通用定時器定期地產(chan) 生中斷。在定時器發出中斷時,指標寄存器的內(nei) 容被讀出並存儲(chu) 在存儲(chu) 器中。在主機發出請求時,存儲(chu) 的指標寄存器數據通過BTC通道發送到PC。BTC通道支持數據傳(chuan) 輸速率高達3Mbps。
Now consider an example program where multiple buffers are mapped in the DDR memory and memory DMA's are used to transfers data between these buffers.現在考慮一個(ge) 示例程序,該程序有多個(ge) 緩存影射到DDR存儲(chu) 器中,並使用存儲(chu) 器的DMA在這些緩存之間傳(chuan) 輸數據。#p#分頁標題#e#
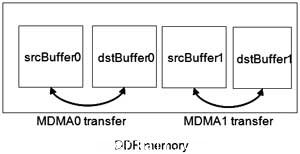
圖4 在外部DDR存儲(chu) 器中多組數據傳(chuan) 輸的例子
在這個(ge) 例子中,MDMA0從(cong) srcBuffer0向dstBuffer0傳(chuan) 輸4KB的數據,MDMA1從(cong) srcBuffer01向dstBuffer1傳(chuan) 輸4KB的數據。最開始隻啟動MDMA0,在MDMA0數據傳(chuan) 輸完成後,MDMA1通道啟用,反之亦然,這種方式導致在各個(ge) 時間區間存儲(chu) 器組訪問數發生變化。在這個(ge) 例子中,指標寄存器一個(ge) 快照顯示了下麵情況(見圖5)。從(cong) 這個(ge) 數字無法看出哪個(ge) 存儲(chu) 器組引起頁錯失,以及哪個(ge) 數據流通道應對產(chan) 生頁錯失負責。周期性地多次觀測指標寄存器可幫助我們(men) 找到帶寬利用率低的原因。
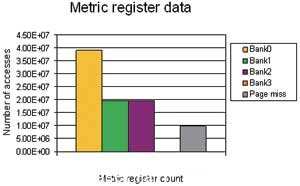
圖5 例2指標寄存器數據的一個(ge) 快照
我們(men) 將利用上述實驗裝置來記錄指標寄存器數據。可使用在PC上獲得的指標寄存器數據來繪製在頁錯失和存儲(chu) 器組訪問之間的相關(guan) 圖,采用MATLAB等數學工具箱來分析該數據。從(cong) 該圖可以看出,大多數頁錯失是由存儲(chu) 器組0訪問引起的。
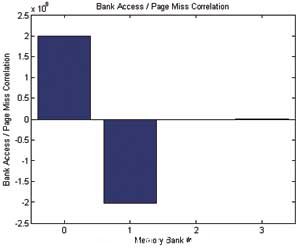
圖6 頁錯失和DDR Bankx訪問之間的相關(guan) 性
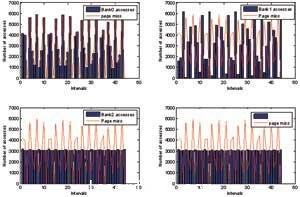
圖7 存儲(chu) 器組訪問與(yu) 頁錯失
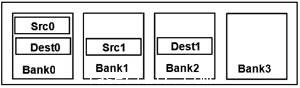
圖8 例2未經優(you) 化的布局
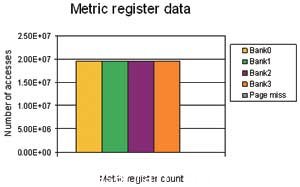
圖9 緩存布局優(you) 化
利用連接程序描述文件(ldf)或使用Blackfin處理器存儲(chu) 器窗口,可以確定哪些緩存影射到這些組,並把它們(men) 重新分別映射到其他組,從(cong) 而減少頁錯失。
總線授權計數寄存器
總線授權計數寄存器(EBIU_DDRGCx)可幫助我們(men) 了解各個(ge) 係統總線(EAB和DEBx總線)的資源利用率。實際上,這將有助於(yu) 確定總線仲裁策略並確保實現高效的DMA和外部存儲(chu) 器資源共享。
Blackfin BF54x係列處理器對外部總線提供可編程優(you) 先級設置功能。另外,該係列處理器還把幾個(ge) 外設DMA和存儲(chu) 器DMA映射到多個(ge) DMA控製器上,為(wei) 實現高效資源管理提供了額外的靈活性。
考慮一個(ge) 從(cong) 照相機獲得視頻數據的例子,壓縮算法運行在Blackfin上,經壓縮的視頻數據通過USB總線從(cong) Blackfin發送給PC。觀測結果表明USB吞吐率相當低,無法實時傳(chuan) 輸壓縮的視頻數據。可能的原因之一是USB總線由於(yu) 係統中存在其他高優(you) 先級任務被掛起。對於(yu) 這種情況,我們(men) 可以使用授權計數寄存器快速地進行驗證。同上,我們(men) 觀測指標寄存器在一段時間區間內(nei) 的數據。在幾個(ge) 時間區間內(nei) 指標寄存器的數據揭示出DEB2總線(USB總線)在與(yu) EAB總線(內(nei) 核總線)競爭(zheng) ,因而限製了USB對DDR存儲(chu) 器的訪問。
在默認情況下,內(nei) 核擁有比USB接口更高的外部存儲(chu) 器訪問優(you) 先權。對於(yu) 當前的應用,USB總線的實時要求具有比內(nei) 核更高的優(you) 先級。因此,我們(men) 必須使用其中的一個(ge) 總線仲裁寄存器提高USB相對於(yu) 內(nei) 核的優(you) 先級,從(cong) 而解決(jue) 這個(ge) 問題。
總線授權計數寄存器也可與(yu) 存儲(chu) 器組訪問寄存器配合使用,以了解在給定的時間區間內(nei) 哪個(ge) 總線最活躍,並找到頁錯失之間的關(guan) 聯和在給定時間區間的總線活動情況。存儲(chu) 器組訪問計數、引起頁錯失的總線以及哪些資源在利用總線等信息可揭示出那些低效的代碼或數據存儲(chu) 器布局。
轉載請注明出處。

 相關文章
相關文章
 熱門資訊
熱門資訊
 精彩導讀
精彩導讀

























 關注我們
關注我們