





微軟技術院士黃學東(dong) 微軟技術院士,負責微軟語音、自然語言和機器翻譯工作的黃學東(dong) 博士表示,這是自然語言處理領域的一項裏程碑式的成就。“這是我們(men) 的情懷,是非常有意義(yi) 的工作,”黃學東(dong) 告訴新智元:“消除語言障礙,讓人們(men) 能更好地溝通,非常有價(jia) 值,值得我們(men) 多年來不斷為(wei) 此付出努力。”
黃學東(dong) 驕傲地說,2015年微軟率先在圖像識別ImageNet數據集達到人類水平,2016年在Switchboard對話語義(yi) 識別達到人類水平,2017在斯坦福問答數據集SQuAD上達到人類水平,今天又在機器翻譯上達到人類水平,一路走來,微軟的進步激動人心,“這是我們(men) 共同的成就,我們(men) 是站在同行的肩膀上往上走”。
黃學東(dong) 表示,微軟語音和NLP組在成立時,便立下了要在兩(liang) 年後將機器翻譯做到人類專(zhuan) 業(ye) 水平的目標。如今,這一目標提前實現,“除了計算力的大幅提高,深度學習(xi) 方法的提高,我們(men) 還結合了以前在Switchboard上取得的經驗,數據也做了很多整理,比如去除低質量的訓練數據,等等。”黃學東(dong) 說。
“這既是技術上的突破,也是工程上的突破,是技術和工程的完美結合,隻有把過程中的每一件事情都做好,才能得到這樣的結果。”
NLP裏程碑式突破:首個(ge) 媲美人類專(zhuan) 業(ye) 譯者的機器翻譯係統
這次微軟的翻譯係統是在數據集WMT-17的新聞數據集newstest2017上取得了上述成果。WMT是機器翻譯領域的國際頂級評測比賽之一。WMT數據集也是機器翻譯領域一個(ge) 公認的主流數據集。其中,newstest2017新聞報道測試集由產(chan) 業(ye) 界和學術界的合作夥(huo) 伴共同開發,包括來自新聞評論語料庫的約332K個(ge) 句子對,來自聯合國平行語料庫的15.8M個(ge) 句子對,以及來自CWMT語料庫的9M個(ge) 句子對。
雖然研究人員隻進行了漢譯英的測試,但黃學東(dong) 表示,英譯漢結果也應該並無不同。“從(cong) 技術上說,漢譯英和英譯漢是相同的,隻要有足夠的數據。”
為(wei) 了確保翻譯結果準確且達到人類的翻譯水平,微軟研究團隊還邀請了雙語語言顧問,將微軟的翻譯結果與(yu) 兩(liang) 個(ge) 獨立的人工翻譯結果進行了比較評估(全部盲測)。黃學東(dong) 告訴新智元:“當機器翻譯質量很差的時候,使用BLEU評分還行,但是當機器翻譯質量提高以後,就需要靠人類來評價(jia) 。”
具體(ti) 說,當100分是標準滿分時,微軟的係統得分69.9,專(zhuan) 業(ye) 譯者68.6,而眾(zhong) 包翻譯得分為(wei) 67.6。
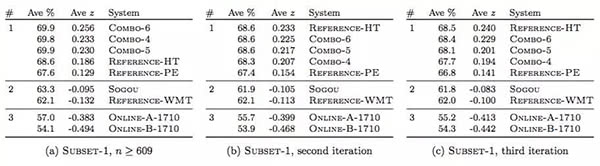
人類專(zhuan) 家的評估結果(部分):其中,Reference-HT為(wei) 純人工翻譯;Reference-PE為(wei) 使用Google Translate加人工後期編輯的翻譯;Reference-WMT是WMT原始翻譯,包含錯誤;Online-A-1710是2017年10月16日收集的Microsoft翻譯商用係統(production system);Online-B-1710是2017年10月16日收集的穀歌翻譯商用係統;Sogou是搜狗NMT翻譯係統,這是在2017年WMT中英機器翻譯競賽的冠軍(jun) 。
機器翻譯提前7年超越人類譯者,人工智能再下一城
機器翻譯是科研人員攻堅了數十年的研究領域,曾經很多人都認為(wei) 機器翻譯根本不可能達到人類翻譯的水平。
2017年中旬,牛津大學麵向機器學習(xi) 研究人員做了一次大規模調查,調查的內(nei) 容是他們(men) 對 AI 進展的看法。這些研究人員預測,未來10年,AI 將在許多活動中超過人類,具體(ti) 預測見下表:
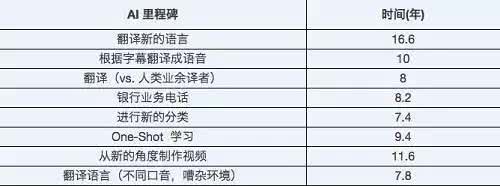
微軟的這次突破,將機器翻譯超越人類業(ye) 餘(yu) 譯者的時間,提前了整整7年,遠遠超出了眾(zhong) 多ML研究人員的預想。
雖然此次突破意義(yi) 非凡,但微軟研究人員也提醒大家,這並不代表人類已經完全解決(jue) 了機器翻譯的問題,隻能說明我們(men) 離終極目標又更近了一步。微軟亞(ya) 洲研究院副院長、自然語言計算組負責人周明表示,在WMT17測試集上的翻譯結果達到人類水平很鼓舞人心,但仍有很多挑戰需要解決(jue) ,比如在實時的新聞報道上測試係統等。
微軟機器翻譯團隊研究經理Arul Menezes表示,團隊想要證明的是:當一種語言對(比如中-英)擁有較多的訓練數據,且測試集中包含的是常見的大眾(zhong) 類新聞詞匯時,那麽(me) 在人工智能技術的加持下,機器翻譯係統的表現可以與(yu) 人類媲美。
突破當前神經機器翻譯範式局限,性能再上一個(ge) 數量級
為(wei) 了能夠取得中-英翻譯的裏程碑式突破,來自微軟亞(ya) 洲研究院和雷德蒙研究院的三個(ge) 研究組,進行了跨越中美時區、跨越研究領域的聯合創新。
在這篇有24位作者的論文《機器翻譯:中英新聞翻譯方麵達到與(yu) 人類媲美的水平》(Achieving Human Parity on Automatic Chinese to English News Translation )中,微軟研究團隊描述了他們(men) 為(wei) 新聞漢英翻譯任務在規模數據集上實現人類水平所作的努力。
在論文中,作者表示他們(men) 解決(jue) 了當前NMT範式的一些局限。 他們(men) 的研究主要貢獻包括:利用翻譯問題的對偶性(duality),使模型能夠從(cong) 源語言到目標語言(Source to Target)和從(cong) 目標語言到源語言(Target to Source)這兩(liang) 個(ge) 方向的翻譯中學習(xi) 。同時,這讓我們(men) 能同時從(cong) 有監督和無監督的源數據和目標數據中學習(xi) 。具體(ti) 而言,我們(men) 利用通用的對偶學習(xi) (dual learning)方法,並引入聯合訓練(Joint Training)算法,通過在一個(ge) 統一的框架中反複提高從(cong) 源語言到目標語言翻譯和從(cong) 目標語言到源語言翻譯的模型,從(cong) 而增強單語源和目標數據的效果。
NMT係統從(cong) 左到右自動回歸解碼,這意味著在按順序生成輸出期間,之前的錯誤將被放大,並可能誤導後續生成的結果。這隻能部分通過波束搜索(beam search)進行補救。我們(men) 提出了兩(liang) 種方法來緩解這個(ge) 問題:推敲網絡(Deliberation Networks),這是一種基於(yu) 雙路解碼來優(you) 化翻譯的方法;以及在兩(liang) 個(ge) Kullback-Leibler(KL)散度正則化項上的新訓練目標,鼓勵從(cong) 左到右和從(cong) 右到左的解碼結果變得一致。
由於(yu) NMT非常容易受到嘈雜訓練數據、數據中的罕見事件以及總體(ti) 訓練數據質量的影響,論文還討論了數據選擇和過濾的方法,包括跨語言句子表示。
最後,我們(men) 發現我們(men) 的係統是完全互補的,因此可以從(cong) 係統組合中獲益很多,最終實現了機器翻譯達到人類水平的目標。
四大技術加持,神經機器翻譯將成今後機器翻譯絕對主流
其中,微軟亞(ya) 洲研究院機器學習(xi) 組將他們(men) 的最新研究成果——對偶學習(xi) (Dual Learning)和推敲網絡(Deliberation Networks)應用在了此次取得突破的機器翻譯係統中。其中,對偶學習(xi) 利用的是人工智能任務的天然對稱性。當我們(men) 把訓練集中的一個(ge) 中文句子翻譯成英文之後,係統會(hui) 將相應的英文結果再翻譯回中文,並與(yu) 原始的中文句子進行比對,進而從(cong) 這個(ge) 比對結果中學習(xi) 有用的反饋信息,對機器翻譯模型進行修正。

微軟亞(ya) 洲研究院副院長、機器學習(xi) 組負責人劉鐵岩
而推敲網絡則類似於(yu) 人們(men) 寫(xie) 文章時不斷推敲、修改的過程。通過多輪翻譯,不斷地檢查、完善翻譯的結果,從(cong) 而使翻譯的質量得到大幅提升。“我們(men) 在深度學習(xi) 和自然語言這兩(liang) 者中間找到了一個(ge) 平衡點,我們(men) 想通過對機器翻譯的研究,從(cong) 自然語言的角度對機器學習(xi) 做進一步的理解,找到一些直覺,再通過這個(ge) 直覺反過來影響機器學習(xi) 研究的路線,走出盲目嚐試的狀態。”微軟亞(ya) 洲研究院副院長、機器學習(xi) 組負責人劉鐵岩說。
那研究人員從(cong) 推敲網絡中獲得的直覺是什麽(me) 呢?他們(men) 發現,人在做翻譯的時候,在看見或聽完源語言後,腦子裏會(hui) 形成一個(ge) 觀點,這其實就是編碼的過程。但是,我們(men) 真正把這句話當成目標語言講出來,實際上是三思而後行的。我們(men) 不會(hui) 一個(ge) 字一個(ge) 字往出蹦,我們(men) 會(hui) 先醞釀一下要怎麽(me) 講,如果是文字翻譯,還可能不斷地修改,讓語句更加通順或者優(you) 美。
“我們(men) 常常說,人會(hui) 做推敲的事情,是‘僧敲月下門’還是‘僧推月下門’,要琢磨琢磨,上下文關(guan) 係用哪個(ge) 字更好,如何在一個(ge) 機器學習(xi) 的模型中將這種推敲過程體(ti) 現出來,就是推敲網絡所要去嚐試的一個(ge) 點。”劉鐵岩告訴新智元。

推敲,也就是在解碼器,或者說在文本生成的過程多做點文章,把人的一些直覺放進去。“在我們(men) 的DeliberationNet裏麵,解碼器是有多層的,解碼器先做一遍,可能翻譯得不太好,但從(cong) 頭到尾翻譯完了,這句翻譯會(hui) 再扔給下一個(ge) 解碼器再做一遍,這個(ge) 過程可以不斷反複,不停地去修改之前翻譯的完整結果,這其實就在做推敲。我們(men) 發現,這樣推敲後的結果比隻過一次要好很多,多過一次時間代價(jia) 會(hui) 增多,但是結果會(hui) 更好。”
微軟亞(ya) 洲研究院副院長、自然語言計算組負責人周明周明帶領的自然語言計算組多年來一直致力於(yu) 攻克機器翻譯,這一自然語言處理領域最具挑戰性的研究任務。周明表示,“由於(yu) 翻譯沒有唯一的標準答案,它更像是一種藝術,因此需要更加複雜的算法和係統去應對。”
基於(yu) 之前的研究積累,自然語言計算組在此次的係統模型中增加了另外兩(liang) 項新技術:聯合訓練(Joint Training)和一致性規範(Agreement Regularization),以提高翻譯的準確性。聯合訓練可以理解為(wei) 用迭代的方式去改進翻譯係統,用中英翻譯的句子對去補充反向翻譯係統的訓練數據集,同樣的過程也可以反向進行。一致性規範則讓翻譯可以從(cong) 左到右進行,也可以從(cong) 右到左進行,最終讓兩(liang) 個(ge) 過程生成一致的翻譯結果。

左邊是聯合訓練:從(cong) 源語言到目標語言翻譯(Source to Target)P(y|x) 與(yu) 從(cong) 目標語言到源語言翻譯(Target to Source)P(x|y);右邊是一致性規範
這次使用的技術,從(cong) 對偶學習(xi) (Dual Learning)、推敲網絡(Deliberation Network)到一致性規範(Agreement Regularization),都屬於(yu) 神經機器翻譯(NMT)方法。而黃學東(dong) 也認為(wei) ,今後的機器翻譯領域,NMT也將成為(wei) 絕對主流。“相比統計機器翻譯,神經機器翻譯有一個(ge) 很大的提高,而這次我們(men) 新的係統,相比普通的神經機器翻譯,又有一個(ge) 很大的提高。”黃學東(dong) 說:“我們(men) 這次的係統是把很多不同的機器翻譯係統組合到一起,這些係統每一個(ge) 都能獨立工作,輸出結果,最終,我們(men) 再將這些結果綜合起來,輸出一個(ge) 最好的結果。”
深度學習(xi) NLP掌握著實現強人工智能的鑰匙
對於(yu) 語音識別等其它人工智能任務來說,判斷係統的表現是否可與(yu) 人類媲美相當簡單,因為(wei) 理想結果對人和機器來說完全相同,研究人員也將這種任務稱為(wei) 模式識別任務。
然而,機器翻譯卻是另一種類型的人工智能任務,即使是兩(liang) 位專(zhuan) 業(ye) 的翻譯人員對於(yu) 完全相同的句子也會(hui) 有略微不同的翻譯,而且兩(liang) 個(ge) 人的翻譯都不是錯的。那是因為(wei) 表達同一個(ge) 句子的“正確的”方法不止一種。 周明表示:“這也是為(wei) 什麽(me) 機器翻譯比純粹的模式識別任務複雜得多,人們(men) 可能用不同的詞語來表達完全相同的意思,但未必能準確判斷哪一個(ge) 更好。”
複雜性讓機器翻譯成為(wei) 一個(ge) 極有挑戰性的問題,但也是一個(ge) 極有意義(yi) 的問題。劉鐵岩認為(wei) ,我們(men) 不知道哪一天機器翻譯係統才能在翻譯任何語言、任何類型的文本時,都能在“信、達、雅”等多個(ge) 維度上達到專(zhuan) 業(ye) 翻譯人員的水準。不過,他對技術的進展表示樂(le) 觀,因為(wei) 每年微軟的研究團隊以及整個(ge) 學術界都會(hui) 發明大量的新技術、新模型和新算法,“我們(men) 可以預測的是,新技術的應用一定會(hui) 讓機器翻譯的結果日臻完善。”
研究團隊還表示,他們(men) 計劃將此次技術突破推廣到其他語言上麵,同時應用到微軟的商用多語言翻譯係統產(chan) 品中。
黃學東(dong) 認為(wei) ,神經機器翻譯,或者說深度學習(xi) ,最激動人心的地方在於(yu) ,它能夠學會(hui) 自然語言內(nei) 部的embedded feature,把語言的結構,語義(yi) 結構和語義(yi) 的表示學習(xi) 出來,再反饋到係統,從(cong) 而實現自然語言理解的突破。
“機器學習(xi) 需要很多數據,NLP沒有很多標注的數據,把表示學習(xi) 出來,還能推廣到其他係統。”黃學東(dong) 說:“NLP掌握著今後實現強人工智能的鑰匙。”
轉載請注明出處。

 相關文章
相關文章
 熱門資訊
熱門資訊
 精彩導讀
精彩導讀


















 關注我們
關注我們