




來源:MIT
編輯:張佳
【新智元導讀】MIT的研究人員開發出一種新型 “光子” 芯片,它使用光而不是電,並且在此過程中消耗相對較少的功率。該芯片用於(yu) 處理大規模神經網絡的效率比現有的計算機高出數百萬(wan) 倍。模擬結果表明,光子芯片運行光神經網絡的效率是其電子芯片的1000萬(wan) 倍。
神經網絡是一種機器學習(xi) 模型,廣泛用於(yu) 機器人目標識別、自然語言處理、藥物開發、醫學成像和驅動無人駕駛汽車等任務。使用光學現象加速計算的新型光學神經網絡可以比其他電子對應物更快、更有效地運行。
但隨著傳(chuan) 統神經網絡和光學神經網絡越來越複雜,它們(men) 消耗了大量的能量。為(wei) 了解決(jue) 這個(ge) 問題,研究人員和包括穀歌、IBM和特斯拉在內(nei) 的主要科技公司開發了“人工智能加速器”,這是一種專(zhuan) 門的芯片,可以提高培訓和測試神經網絡的速度和效率。
對於(yu) 電子芯片,包括大多數人工智能加速器,有一個(ge) 理論上的最低能耗限製。最近,MIT的研究人員開始為(wei) 光神經網絡開發光子加速器。這些芯片執行數量級的效率更高,但它們(men) 依賴於(yu) 一些體(ti) 積龐大的光學元件,這些元件限製了它們(men) 在相對較小的神經網絡中的使用。
在《物理評論X》上發表的一篇論文中,MIT的研究人員描述了一種新型光子加速器,它使用更緊湊的光學元件和光信號處理技術,以大幅降低功耗和芯片麵積。這使得芯片可以擴展到神經網絡,比對應的芯片大幾個(ge) 數量級。
比傳(chuan) 統電子加速器的能耗極限低1000萬(wan) 倍以上
神經網絡在MNIST圖像分類數據集上的模擬訓練表明,加速器理論上可以處理神經網絡,比傳(chuan) 統電子加速器的能耗極限低1000萬(wan) 倍以上,比光子加速器的能耗極限低1000倍左右。研究人員現在正在研製一種原型芯片來實驗證明這一結果。
“人們(men) 正在尋找一種能夠計算出超出基本能耗極限的技術,”電子研究實驗室的博士後Ryan Hamerly說:“光子加速器是很有前途的……但我們(men) 的動機是建造一個(ge) (光子加速器)可以擴展到大型神經網絡。”
這些技術的實際應用包括降低數據中心的能耗。“對於(yu) 運行大型神經網絡的數據中心的需求越來越大,而且隨著需求的增長,它越來越難以計算,”合著者、電子研究實驗室的研究生Alexander Sludds說,其目的是“利用神經網絡硬件滿足計算需求……以解決(jue) 能源消耗和延遲的瓶頸”。
與(yu) Sludds和Hamerly合寫(xie) 該論文的有:RLE研究生、聯合作者Liane Bernstein;麻省理工學院物理教授Marin Soljacic;一名麻省理工學院電氣工程和計算機科學副教授Dirk Englund;一名RLE的研究員,以及量子光子學實驗室的負責人。
依賴於(yu) 一種更緊湊、節能的“光電”方案
神經網絡通過許多包含互聯節點(稱為(wei) “神經元”)的計算層來處理數據,從(cong) 而在數據中找到模式。神經元接收來自其上遊“鄰居”的輸入,並計算一個(ge) 輸出信號,該信號被發送到下遊更遠的神經元。每個(ge) 輸入也被分配一個(ge) “權重”,一個(ge) 基於(yu) 其對所有其他輸入的相對重要性的值。隨著數據在各層中“深入”傳(chuan) 播,網絡逐漸學習(xi) 更複雜的信息。最後,輸出層根據整個(ge) 層的計算生成預測。
所有人工智能加速器的目標都是減少在神經網絡中的特定線性代數步驟(稱為(wei) “矩陣乘法”)中處理和移動數據所需的能量。在那裏,神經元和權重被編碼成單獨的行和列表,然後結合起來計算輸出。
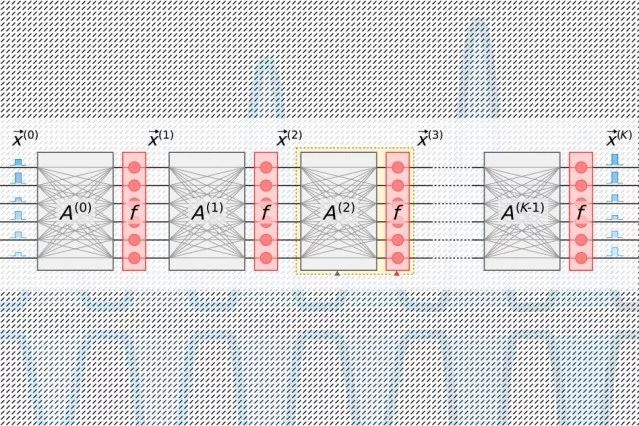
在傳(chuan) 統的光子加速器中,脈衝(chong) 激光編碼了一個(ge) 層中每個(ge) 神經元的信息,然後流入波導並通過分束器。產(chan) 生的光信號被送入一個(ge) 稱為(wei) “Mach-Zehnder 幹涉儀(yi) ”的正方形光學元件網格中,該網格被編程為(wei) 執行矩陣乘法。幹涉儀(yi) 用每個(ge) 重量的信息進行編碼,使用處理光信號和重量值的信號幹擾技術來計算每個(ge) 神經元的輸出。但是有一個(ge) 縮放問題:對於(yu) 每個(ge) 神經元,必須有一個(ge) 波導管,對於(yu) 每個(ge) 重量,必須有一個(ge) 幹涉儀(yi) 。由於(yu) 重量的數量與(yu) 神經元的數量成正比,那些幹涉儀(yi) 占用了大量的空間。
“你很快就會(hui) 意識到輸入神經元的數量永遠不會(hui) 超過100個(ge) 左右,因為(wei) 你不能在芯片上安裝那麽(me) 多的元件,”Hamerly說,“如果你的光子加速器不能每層處理100個(ge) 以上的神經元,那麽(me) 很難將大型神經網絡應用到這種結構中。”
研究人員的芯片依賴於(yu) 一種更緊湊、節能的“光電”方案,該方案利用光信號對數據進行編碼,但使用“平衡零差檢測”進行矩陣乘法。這是一種在計算兩(liang) 個(ge) 光信號的振幅(波高)的乘積後產(chan) 生可測量電信號的技術。
光脈衝(chong) 編碼的信息輸入和輸出神經元的每個(ge) 神經網絡層——用來訓練網絡——通過一個(ge) 單一的通道流動。用矩陣乘法表中整行權重信息編碼的單獨脈衝(chong) 通過單獨的通道流動。將神經元和重量數據傳(chuan) 送到零差光電探測器網格的光信號。光電探測器利用信號的振幅來計算每個(ge) 神經元的輸出值。每個(ge) 檢測器將每個(ge) 神經元的電輸出信號輸入一個(ge) 調製器,該調製器將信號轉換回光脈衝(chong) 。光信號成為(wei) 下一層的輸入,以此類推。
這種設計隻需要每個(ge) 輸入和輸出神經元一個(ge) 通道,並且隻需要和神經元一樣多的零差光電探測器,而不需要重量。因為(wei) 神經元的數量總是遠遠少於(yu) 重量,這就節省了大量的空間,所以芯片能夠擴展到每層神經元數量超過一百萬(wan) 的神經網絡。
找到最佳位置
有了光子加速器,信號中會(hui) 有不可避免的噪聲。注入芯片的光線越多,噪音越小,精確度也越高——但這會(hui) 變得非常低效。輸入光越少,效率越高,但會(hui) 對神經網絡的性能產(chan) 生負麵影響。但是有一個(ge) “最佳點”,Bernstein說,它在保持準確度的同時使用最小的光功率。
人工智能加速器的最佳位置是以執行一次兩(liang) 個(ge) 數相乘的單一操作(如矩陣相乘)需要多少焦耳來衡量的。現在,傳(chuan) 統的加速器是用皮焦(picojoules)或萬(wan) 億(yi) 焦耳(joule)來測量的。光子加速器以attojoules測量,效率高出一百萬(wan) 倍。
在模擬中,研究人員發現他們(men) 的光子加速器可以以低於(yu) attojoules的效率運行。 “在失去準確性之前,你可以發送一些最小的光功率。我們(men) 的芯片的基本限製比傳(chuan) 統的加速器低得多......並且低於(yu) 其他光子加速器,”Bernstein表示。
轉載請注明出處。

 相關文章
相關文章
 熱門資訊
熱門資訊
 精彩導讀
精彩導讀


















 關注我們
關注我們