




人臉識別的研究可以追溯到上個(ge) 世紀六、七十年代,經過幾十年的曲折發展已日趨成熟,構建人臉識別係統需要用到一係列相關(guan) 技術,包括人臉圖像采集、人臉定位、人臉識別預處理、身份確認以及身份查找等 。而人臉識別在基於(yu) 內(nei) 容的檢索、數字視頻處理、視頻檢測等方麵有著重要的應用價(jia) 值,可廣泛應用於(yu) 各類監控場合,因此具有廣泛的應用前景。OpenCV是Intel 公司支持的開源計算機視覺庫。它輕量級而且高效--由一係列 C 函數和少量 C++ 類構成,實現了圖像處理和計算機視覺方麵的很多通用算法,作為(wei) 一個(ge) 基本的計算機視覺、圖像處理和模式識別的開源項目,OpenCV 可以直接應用於(yu) 很多領域,其中就包括很多可以應用於(yu) 人臉識別的算法實現,是作為(wei) 第二次開發的理想工具。
1 係統組成
本文的人臉識別係統在Linux 操作係統下利用QT庫來開發圖形界麵,以OpenCV 圖像處理庫為(wei) 基礎,利用庫中提供的相關(guan) 功能函數進行各種處理:通過相機對圖像數據進行采集,人臉檢測主要是調用已訓練好的Haar 分類器來對采集的圖像進行模式匹配,檢測結果利用PCA 算法可進行人臉圖像訓練與(yu) 身份識別,而人臉表情識別則利用了Camshift 跟蹤算法和Lucas–Kanade 光流算法。
2 搭建開發環境
采用德國Basler acA640-100gc 相機,PC 機上的操作係統是Fedora 10,並安裝編譯器GCC4.3,QT 4.5和OpenCV2.2 軟件工具包,為(wei) 了處理視頻,編譯OpenCV 前需編譯FFmpeg,而FFmpeg 還依賴於(yu) Xvid庫和X264 庫。
3 應用係統開發
程序主要流程如圖1 所示。
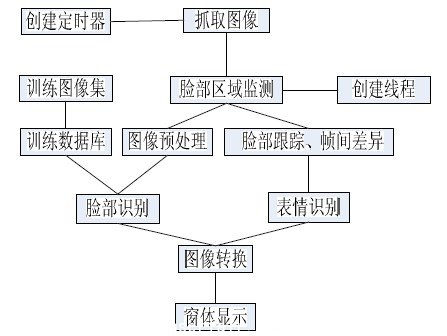
圖1 程序流程(visio)
3.1 圖像采集
圖像采集模塊可以通過cvCaptureFromAVI()從(cong) 本地保存的圖像文件或cvCaptureFromCam()從(cong) 相機得到圖像,利用cvSetCaptureProperty()可以對返回的結構進行設置:
IplImage *frame;CvCapture* cAMEra = 0;
camera = cvCaptureFromCAM( 0 );
cvSetCaptureProperty(camera,
CV_CAP_PROP_FRAME_WIDTH, 320 );
cvSetCaptureProperty(camera,
CV_CAP_PROP_FRAME_HEIGHT, 240 );
然後利用start()函數開啟QTimer 定時器,每隔一段時間發送信號調用自定義(yi) 的槽函數,該槽函數用cvGrabFrame()從(cong) 視頻流中抓取一幀圖像放入緩存,再利用CvRetrieveFrame()從(cong) 內(nei) 部緩存中將幀圖像讀出用於(yu) 接下來的處理與(yu) 顯示。在qt 中顯示之前,需將IplImage* source 轉換為(wei) QPixmap 類型。
uchar *qImageBuffer = NULL;
/*根據圖像大小分配緩衝(chong) 區*/
qImageBuffer = (uchar*) malloc(source-》width *
source->height * 4 * sizeof(uchar));
/*將緩衝(chong) 區指針拷貝到存取Qimage 的指針中*/
uchar *QImagePtr = qImageBuffer;
/* 獲取源圖像內(nei) 存指針*/Const uchar*#p#分頁標題#e#
iplImagePtr=reinterpret_cast/<uchar*》>(source->imageDat
a);
/*通過循環將源圖像數據拷貝入緩衝(chong) 區內(nei) */
for (int y = 0; y < source->height; ++y){
for (int x = 0; x < source->width; ++x){
QImagePtr[0] = iplImagePtr[0];
QImagePtr[1] = iplImagePtr[1];
QImagePtr[2] = iplImagePtr[2];
QImagePtr[3] = 0;
QImagePtr += 4;
iplImagePtr += 3; }
iplImagePtr+=source->widthStep–3*source->width; }
/*將Qimage 轉換為(wei) Qpixmap*/QPixmap local =
QPixmap::fromImage(QImage(qImageBuffer,source-》wi
dth,source-》height, QImage::Format_RGB32));#p#分頁標題#e#
/*釋放緩衝(chong) 區*/
free(qImageBuffer);
最後利用QLabel 的setPixmap()函數進行顯示。
3.2 圖像預處理
由於(yu) 大部分的臉部檢測算法對光照,臉部大小,位置表情等非常敏感, 當檢測到臉部後需利用cvCvtcolor()轉化為(wei) 灰度圖像,利用cvEqualizeHist()進行直方圖歸一化處理。
3.3 臉部檢測方法
OpenCV采用一種叫做Haar cascade classifier 的人臉檢測器,他利用保存在XML 文件中的數據來確定每一個(ge) 局部搜索圖像的位置,先用cvLoad()從(cong) 文件中加載CvHaarClassifierCascade 變量, 然後利用cvHaarDetectObjects()來進行檢測,函數使用針對某目標物體(ti) 訓練的級聯分類器在圖像中找到包含目標物體(ti) 的矩形區域,並且將這些區域作為(wei) 一序列的矩形框返回,最終檢測結果保存在cvRect 變量中。
3.4 臉部識別方法
識別步驟及所需函數如圖2 所示。
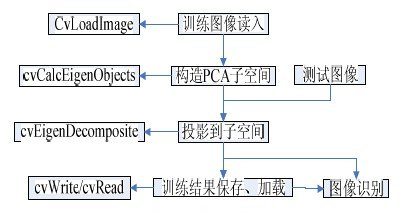
圖2 識別步驟(visio)
PCA 方法(即特征臉方法)是M.Turk 和A.Pentland在文獻中提出的,該方法的基本思想是將圖像向量經過K-L 變換後由高維向量轉換為(wei) 低維向量,並形成低維線性向量空間,即特征子空間,然後將人臉投影到該低維空間,用所得到的投影係數作為(wei) 識別的特征向量。識別人臉時,隻需將待識別樣本的投影係數與(yu) 數據庫中目標樣本集的投影係數進行比對,以確定與(yu) 哪一類最近。
PCA 算法分為(wei) 兩(liang) 步:核心臉數據庫生成階段,即訓練階段以及識別階段。
3.4.1 訓練階段
主要需要經過如下的幾步:
(1) 需要一個(ge) 訓練人臉照片集。
(2) 在訓練人臉照片集上計算特征臉,即計算特征值,保存最大特征值所對應的的M 張圖片。這M 張圖片定義(yi) 了“特征臉空間”(原空間的一個(ge) 子空間)。當有新的人臉添加進來時,這個(ge) 特征臉可以進行更新和重新計算得到。
(3) 在“特征臉空間”上,將要識別的各個(ge) 個(ge) 體(ti) 圖片投影到各個(ge) 軸(特征臉)上,計算得到一個(ge) M 維的權重向量。簡單而言,就是計算得到各個(ge) 個(ge) 體(ti) 所對應於(yu) M 維權重空間的坐標值。
OpenCV 實現為(wei) :先用cvLoadImage()載入圖片並利用cvCvtcolor()轉換為(wei) 灰度圖片,建立自定義(yi) 的迭代標準CvTermCriteria,調用cvCalcEigenObjects()進行PCA 操作,計算出的Eigenface 都存放在向量組成的數組中,利用cvEigenDecomposite()將每一個(ge) 訓練圖片投影在PCA 子空間(eigenspace)上,結果保存在矩陣數組中,用cvWrite《datatype》()將訓練結果保存至XML文件中。下麵圖3 為(wei) 訓練得到的部分特征臉圖像。

圖3 特征臉圖像
3.4.2 身份識別階段
在識別新的人臉圖片時,具體(ti) 的操作方法流程如下:
(1) 基於(yu) 前麵得到的M 個(ge) 特征臉,將新采集的圖片投影到各個(ge) 特征臉,計算得到一個(ge) 權重集合(權重向量)。
(2) 判斷新圖片是否是一幅人臉圖像,即通過判斷圖像是否足夠靠近人臉空間。
(3) 如果是人臉圖像,則根據前麵計算的權重集合(權重向量),利用權重模式將這個(ge) 人臉分類劃歸到初始時計算得到的各個(ge) 個(ge) 體(ti) 或者是成為(wei) 一個(ge) 新 的個(ge) 體(ti) 照片。簡單而言,就是計算新權重到原來各個(ge) 個(ge) 體(ti) 權重的距離,選擇最近的,認為(wei) 是識別成這個(ge) 個(ge) 體(ti) ;如果最近的距離超出閾值,則認為(wei) 是一個(ge) 新的個(ge) 體(ti) 。
(4) 更新特征臉或者是權重模式。
(5) 如果一個(ge) 未知的人臉,出現了很多次,也就意味著,對這個(ge) 人臉沒有記錄,那麽(me) 計算它的特征權重(向量),然後將其添加到已知人臉中[6]。
OpenCV 實現調用cvRead《datatype》()加載訓練結果XML 文件,調cvEigenDecomposite()將采集圖片映射至PCA 子空間,利用最近距離匹配方法SquaredEuclidean Distance,計算要識別圖片同每一個(ge) 訓練結果的距離,找出距離最近的即可。
3.5 臉部表情識別
臉部運動跟蹤利用了Camshift 算法,該算法利用目標的顏色直方圖模型將圖像轉換為(wei) 顏色概率分布圖,初始化一個(ge) 搜索窗的大小和位置,並根據上一幀得到的結果自適應調整搜索窗口的位置和大小, 從(cong) 而定位出當前圖像中目標的中心位置。
Camshift 能有效解決(jue) 目標變形和遮擋的問題,對係統資源要求不高,時間複雜度低,在簡單背景下能夠取得良好的跟蹤效果。
Camshift 的OpenCV 實現分以下幾步:
(1)調用cvCvtColor()將色彩空間轉化到HSI 空間,調用cvSplit()獲得其中的H 分量。
(2) 調用cvCreateHist()計算H 分量的直方圖,即1D 直方圖。
(3) 調用cvCalcBackProject()計算Back Projection.#p#分頁標題#e#
(4) 調用cvCamShift()輸出新的Search Window 的位置和麵積。
我們(men) 利用光流算法評估了兩(liang) 幀圖像的之間的變化,Lucas–Kanade 光流算法是一種兩(liang) 幀差分的光流估計算法。它計算兩(liang) 幀在時間t 到t +δt 之間每個(ge) 每個(ge) 像素點位置的移動。是基於(yu) 圖像信號的泰勒級數,就是對於(yu) 空間和時間坐標使用偏導數。
首先要用到shi-Tomasi 算法,該算法主要用於(yu) 提取特征點,即圖中哪些是我們(men) 感興(xing) 趣需要跟蹤的點,對應函數為(wei) cvGoodFeaturesToTrack(),可以自定義(yi) 第一幀特征點的數目,函數將輸出所找到特征值。接下來是cvCalcOpticalFlowPyrLK 函數, 實現了金字塔中Lucas-Kanade 光流計算的稀疏迭代版本。 它根據給出的前一幀特征點坐標計算當前視頻幀上的特征點坐標。輸入參數包括跟蹤圖像的前一幀和當前幀,以及上麵函數輸出的前一幀圖像特征值,自定義(yi) 的迭代標準,輸出所找到的當前幀的特征值點。這些點可以確定麵部局部區域的特征 如眼部,鼻子高度與(yu) 寬度,嘴部兩(liang) 側(ce) 與(yu) 底部的夾角等等,利用與(yu) 前一幀的特征比較,可得出反應臉部動態變化的參數,這些數據可以與(yu) 臉部的一些簡單表情相關(guan) 聯。下麵圖4 為(wei) 跟蹤眼睛上下眨動的圖像。

圖4 跟蹤眼部上下眨動圖像
4 總結
本文以OpenCV 圖像處理庫為(wei) 核心,以QT 庫所提供的界麵框架為(wei) 基礎,提出了人臉識別係統設計方案,實驗證明本方案具有較好的實用性,可移植性。但仍有許多不足之處,如身份與(yu) 表情識別部分可以通過引入神經網絡或支持向量機SVM 進行分類,可以使識別準確率與(yu) 識別種類數得到提高,這些也是後續工作中步需要改進的。
轉載請注明出處。

 相關文章
相關文章
 熱門資訊
熱門資訊
 精彩導讀
精彩導讀


















 關注我們
關注我們