





靠一個(ge) 攝像頭拍下的圖像做3D目標檢測,究竟有多難?目前最先進係統的成績也不及用激光雷達做出來的1/10。
一份來自劍橋的研究,用單攝像頭的數據做出了媲美激光雷達的成績。
還有好事網友在Twitter上驚呼:
這個(ge) 能不能解決(jue) 特斯拉不用激光雷達的問題?馬斯克你看見了沒?

靠“直覺”判斷
為(wei) 何人單眼能做到3D識別,而相機卻做不到?
因為(wei) 直覺。
人能夠根據遠小近大的透視關(guan) 係,得出物體(ti) 的大小和相對位置關(guan) 係。
而機器識別拍攝的2D照片,是3D圖形在平麵上的投影,已經失去了景深信息。
為(wei) 了識別物體(ti) 遠近,無人車需要安裝激光雷達,通過回波獲得物體(ti) 的距離信息。這一點是隻能獲得2D信息的攝像頭難以做到的。
為(wei) 了讓攝像頭也有3D世界的推理能力,這篇論文提出了一種“正投影特征轉換”(OFT)算法。
作者把這種算法和端到端的深度學習(xi) 架構結合起來,在KITTI 3D目標檢測任務上實現了領先的成績。

這套算法包括5個(ge) 部分:
- 前端ResNet特征提取器,用於從輸入圖像中提取多尺度特征圖。
- 正交特征變換,將每個尺度的基於圖像的特征圖變換為正投影鳥瞰圖表示。
- 自上而下的網絡,由一係列ResNet殘餘單元組成,以一種對圖像中觀察到的觀察效果不變的方式處理鳥瞰圖特征圖。
- 一組輸出頭,為每個物體類和地平麵上的每個位置生成置信分數、位置偏移、維度偏移和方向向量等數據。
- 非最大抑製和解碼階段,識別置信圖中的峰值並生成離散邊界框預測。
效果遠超Mono3D
作者用自動駕駛數據集KITTI中3712張訓練圖像,3769張圖像對訓練後的神經網絡進行檢測。並使用裁剪、縮放和水平翻轉等操作,來增加圖像數據集的樣本數量。
作者提出了根據KITTI 3D物體(ti) 檢測基準評估兩(liang) 個(ge) 任務的方法:最終要求每個(ge) 預測的3D邊界框應與(yu) 相應實際物體(ti) 邊框相交,在汽車情況下至少為(wei) 70%,對於(yu) 行人和騎自行車者應為(wei) 50%。
與(yu) 前人的Mono3D方法對比,OFT在鳥瞰圖平均精確度、3D物體(ti) 邊界識別上各項測試成績上均優(you) 於(yu) 對手。

尤其在探測遠處物體(ti) 時要遠超Mono3D,遠處可識別出的汽車數量更多。甚至在嚴(yan) 重遮擋、截斷的情況下仍能正確識別出物體(ti) 。在某些場景下甚至達到了3DOP係統的水平。

不僅(jin) 在遠距離上,正投影特征轉換(OFT-Net)在對不同距離物體(ti) 進行評估時都都優(you) 於(yu) Mono3D。
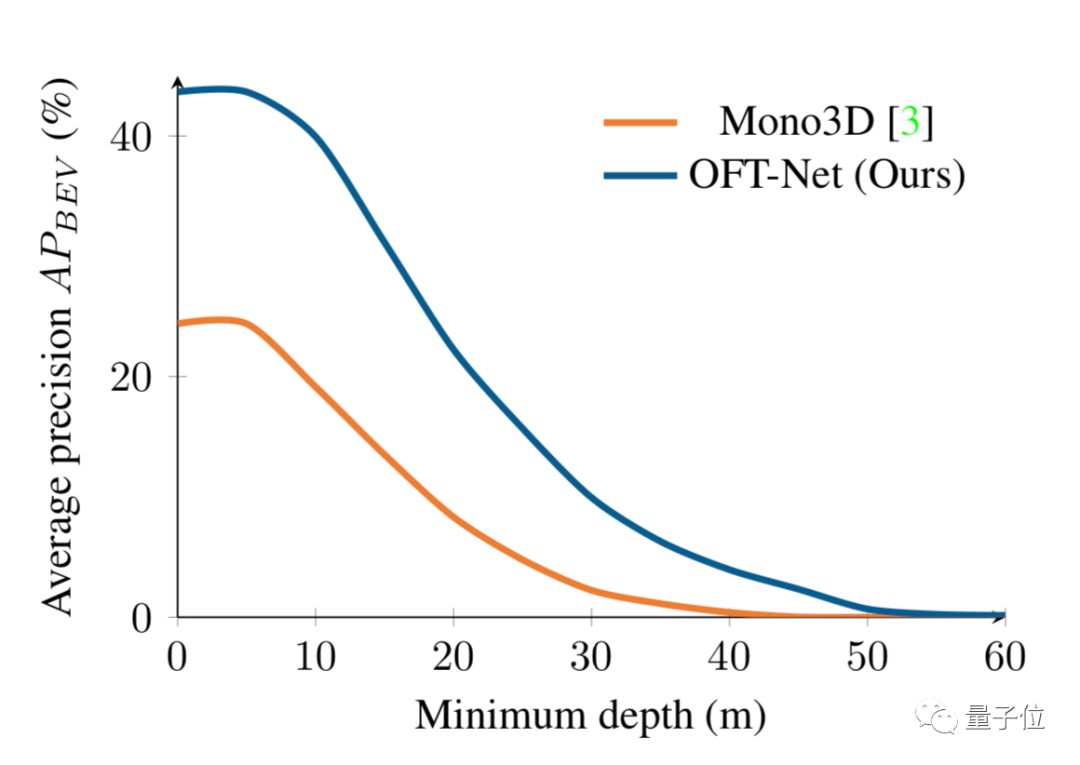
但是與(yu) Mono3D相比,這套係統性能也明顯降低得更慢,作者認為(wei) 是由於(yu) 係統考慮遠離相機的物體(ti) 造成的。
在正交鳥瞰圖空間中的推理顯著提高了性能。為(wei) 了驗證這一說法,論文中還進行了一項研究:逐步從(cong) 自上而下的網絡中刪除圖層。
下圖顯示了兩(liang) 種不同體(ti) 係結構的平均精度與(yu) 參數總數的關(guan) 係圖。
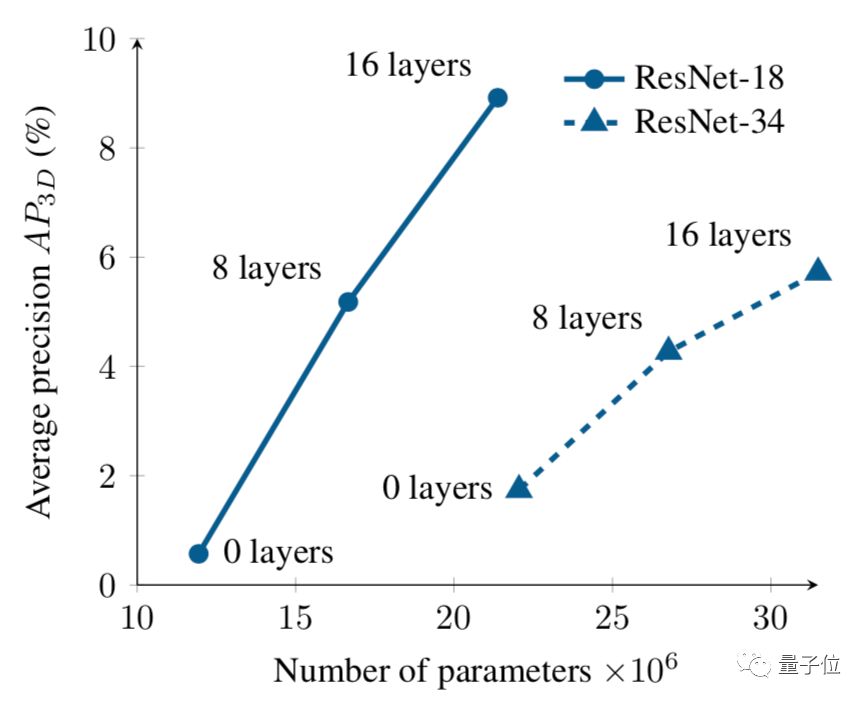
趨勢很明顯,在自上而下網絡中刪除圖層會(hui) 顯著降低性能。
這種性能下降的一部分原因可能是,減少自上而下網絡的規模會(hui) 降低網絡的整體(ti) 深度,從(cong) 而降低其代表性能力。
從(cong) 圖中可以看出,采用具有大型自上而下網絡的淺前端(ResNet-18),可以實現比沒有任何自上而下層的更深層網絡(ResNet-34)更好的性能,盡管有兩(liang) 種架構具有大致相同數量的參數。
資源
論文:
Orthographic Feature Transform for Monocular 3D Object Detection
https://arxiv.org/abs/1811.08188
作者表示等論文正式發表後,就放出預訓練模型和完整的源代碼。
轉載請注明出處。

 相關文章
相關文章
 熱門資訊
熱門資訊
 精彩導讀
精彩導讀

























 關注我們
關注我們